How can we identify relevant topics from moving images?
How can you deal with multiple topics in one video?
How do we choose the best from the many available techniques?
In this blog, I reflect on our first trials using speech recognition as an intermediate step to tackle some of the challenges listed above, and share what we have learned so far.
Topic detection is most notably a subfield of Natural Language Processing (NLP), but there have also been research efforts towards video topic detection¹, and topic detection from speech².
ur focus here is on the latter, using video and speech recognition to improve the user experience for Video on Demand (VoD) or Over-The-Top (OTT) Television services with three different use cases:
Features like these could revolutionise the way we approach viewing behaviour, and increase usability for viewers.
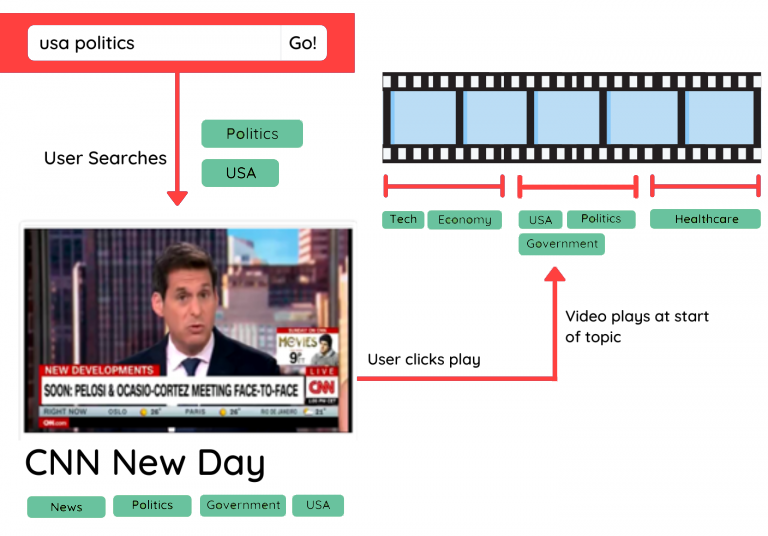
An example: by applying topic detection to a news video, we can detect what each segment is about, when it starts and ends, or recommend it to users based on the topics they are interested in. But what is the best way to approach video topic detection?
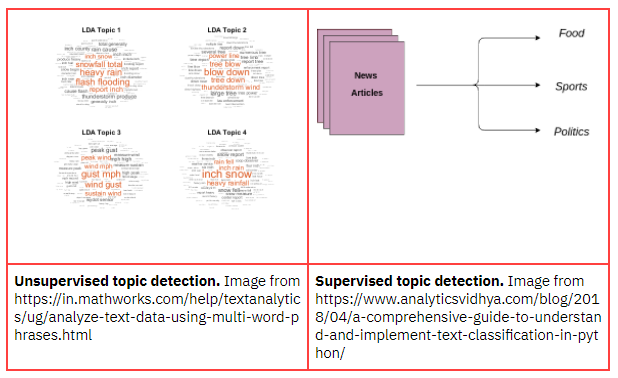
There are two distinct flavours of topic detection, and we need to choose upfront which to use. Unsupervised detection (for example the popular LDA) involves clustering similar words and discovering topics from the emerging clusters. The results are a little like a word cloud and cannot be predicted in advance. Supervised detection involves pre-labelling topics – deciding in advance what is of interest.
Our own mission includes that we present users with a menu of topic choices – a predetermined taxonomy that naturally pushes us towards a supervised topic detection approach.
Extracting meaningful features from a raw video signal is difficult due to the high dimensionality. Every frame is represented by a tensor of (width x height x 3), where the last dimension represents the three RGB channels. For video content this adds up quickly: if we use common image recognition models like ResNet or VGG19 with an input size of 224 x 224, this already gives us 226 million features for a one minute video segment at 25 fps.
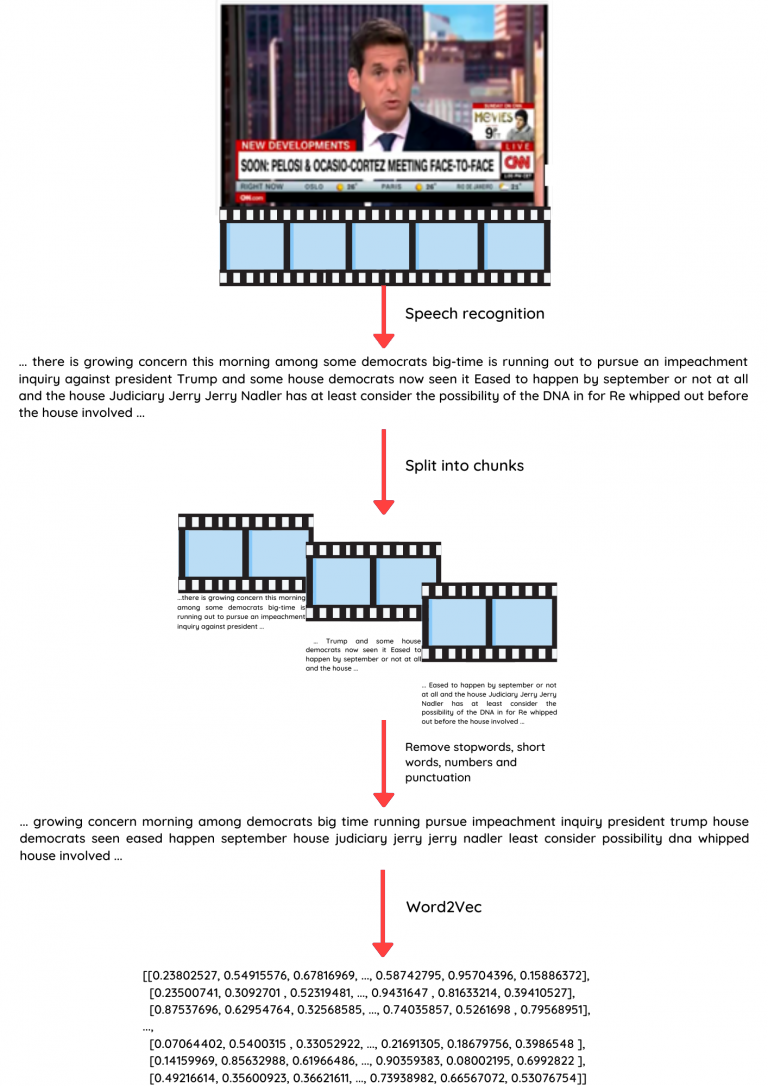
The best way to tackle this problem is to use text transcripts instead of video streams: conversations or voice-overs offer more direct and accessible ways to the topic. You can then apply NLP techniques to further process the data. The easiest and cleanest option is to use subtitle files as a text transcript, but these are clearly not available for all videos. We therefore used a speech recognition engine to extract a text transcript.
Frequently, speech recognition output contains quite a lot of errors, but typically there are enough keywords correctly identified (democrats, impeachment, president, …) to detect sensible topic labels.
We want to detect not only which topics are covered in a video, but the beginning, duration, and end of each topic segment. To enable this, we first split our text transcript into overlapping one-minute chunks and apply topic detection for each chunk separately.
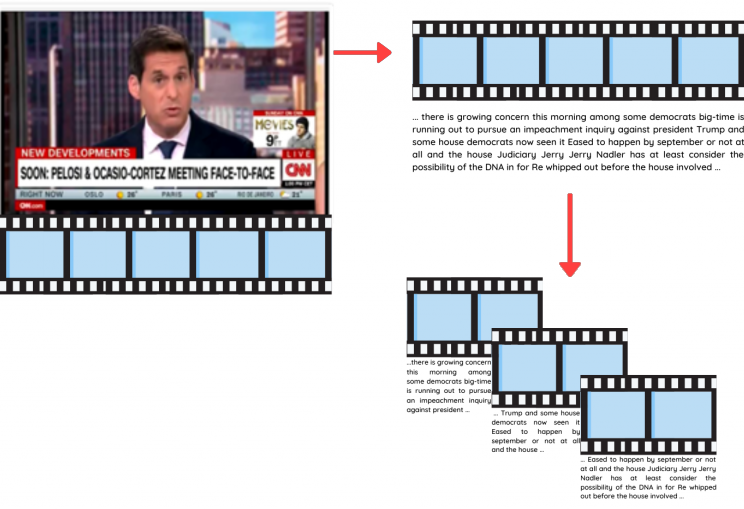
Splitting the transcript into overlapping chunks of one minute
The next step is to translate the words into features that can be used as input to a topic classifier. There are two alternative approaches here. You can use a Bag-of-Words approach, which results in a count of how many times each word appears in your text, or a Word Embedding model that converts every word into a vector, or embedding (numeric values) representing a point in a semantic space, pictured below. The idea behind these vectors is that words that are closely related semantically should have vectors that are similar.
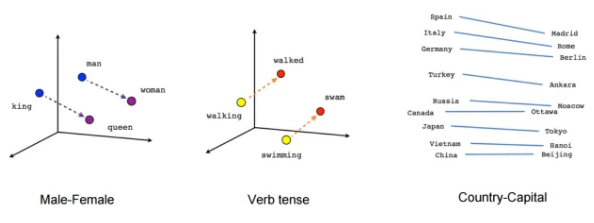
A Word2Vec model represents words as vectors. Similar words have similar vectors, and word relations are translations within the semantic space. Image from https://migsena.com/build-and-visualize-word2vec-model-on-amazon-reviews/
The advantage of using a Bag-of-Words representation is that it is very easy to use (scikit-learn has it built in³), since you don’t need an additional model. The main disadvantage is that the relationship between words is lost entirely. Word Embedding models do encode these relations, but the downside is that you cannot represent words that are not present in the model. For domain-specific texts (where the vocabulary is relatively narrow) a Bag-of-Words approach might save time, but for general language data a Word Embedding model is a better choice for detecting specific content. Since our data is general language from television content, we chose to use a Word2Vec model pre-trained on Wikipedia data4. Gensim5 is a useful library which makes loading or training Word2Vec models quite simple.
Text transcripts are first preprocessed by removing stopwords, very short words, punctuation and numbers.
Original Transcript
... there is growing concern this morning among some democrats big-time is running out to pursue an impeachment inquiry against president Trump and some house democrats now seen it Eased to happen by september or not at all and the house Judiciary Jerry Jerry Nadler has at least consider the possibility of the DNA in for Re whipped out before the house involved ...
Preprocessed transcript
… growing concern morning among democrats big time running pursue impeachment inquiry president trump house democrats seen eased happen september house judiciary jerry jerry nadler least consider possibility dna whipped house involved ...
Then, we calculate the word vector of every word using the Word2Vec model. We use the average over the word vectors within the one-minute chunks as features for that chunk. Word2Vec is a relatively simple feature extraction pipeline, and you could try other Word Embedding models, such as CoVe⁶, BERT⁷ or ELMo⁸ (for a quick overview see here⁹) There is no shortage of word representations with cool names, but for our use case the simple approach proved to be surprisingly accurate.
The task of our classifier is to predict which topics are related to a given piece of text, represented as a single vector containing the document embedding.
We can use a simple feedforward neural network, but we must choose the right function for our final layer. For multiple topic labels, a sigmoid output function is the way to go; not softmax. Why? Well, a softmax function will result in a probability distribution between classes – answering relative questions like ‘what is the probability that this document is about topic A compared to the likelihood of topic B?’ This probability inevitably sums to 1.
A sigmoid function, on the other hand, models every class probability as an independent distribution. This means that the model can be interpreted in terms of independent questions like “What is the probability that this document is about topic A? What is the probability that this document is about topic B?”

The below picture shows the full pipeline, going all the way from the source video to the output topic labels, using the steps described in detail in the previous sections.
As a final output, we take the top 5 topics as classified by our model. These are the detected topics for the example video:
Remembering that this model uses noisy speech-to-text transcripts: even with a fairly simple preprocessing pipeline the output is pretty decent! On our internal tests, we found that with this method we reach an average precision of 0.73, an average recall of 0.81, and 88% of the video snippets have at least one correct topic prediction.
1 Allan, J., Carbonell, J. G., Doddington, G., Yamron, J., & Yang, Y. (1998). Topic detection and tracking pilot study final report.
2 Dharanipragada, S., Franz, M., McCarley, J. S., Roukos, S., & Ward, T. (1999). Story segmentation and topic detection for recognized speech. In Sixth European Conference on Speech Communication and Technology.
3 https://scikit-learn.org/stabl... https://fasttext.cc/docs/en/en... McCann, B., Bradbury, J., Xiong, C., & Socher, R. (2017). Learned in translation: Contextualized word vectors. In Advances in Neural Information Processing Systems (pp. 6294-6305).
4 https://fasttext.cc/docs/en/english-vectors.html
5 https://radimrehurek.com/gensim/
6 McCann, B., Bradbury, J., Xiong, C., & Socher, R. (2017). Learned in translation: Contextualized word vectors. In Advances in Neural Information Processing Systems (pp. 6294-6305).
7 Devlin, J., Chang, M. W., Lee, K., & Toutanova, K. (2018). Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805.
8 Peters, M. E., Neumann, M., Iyyer, M., Gardner, M., Clark, C., Lee, K., & Zettlemoyer, L. (2018). Deep contextualized word representations. In Proceedings of NAACL-HLT (pp. 2227-2237).
9 McCann, B., Bradbury, J., Xiong, C., & Socher, R. (2017). Learned in translation: Contextualized word vectors. In Advances in Neural Information Processing Systems (pp. 6294-6305).
April 23, 2020
